
なぜ動かない?QUERY関数のエラーは「第3引数」が原因かも!見出し設定の罠を社労士が徹底解説

「クエリの構文は完璧なはずなのに、なぜかエラーになる…」
「実行したら、見出しにしていたはずの1行目のデータが消えてしまった…」
「特定の列だけ、うまく認識してくれない…」
GoogleスプレッドシートのQUERY関数を使い始めた方が、一度は通る道ではないでしょうか。
非常に便利な関数ですが、時として私たちの意図通りに動いてくれない、気難しい一面も持っています。
こんにちは!社労士事務所ぽけっとです。
給与計算や従業員管理の効率化でQUERY関数は強力な武器になりますが、こうした「謎のエラー」で時間を溶かしてしまっては本末転倒です。
実は、そのエラーの原因…見落としがちな「第3引数」にあるかもしれません。
この記事では、「第3引数」の正しい使い方と、実務で役立つ応用テクニック、そしてQUERY関数で使える主なコマンドについて、網羅的に解説します。
「第3引数」で決まる!QUERY関数の安定動作
まずは、以下のサンプルデータをスプレッドシートのA1セルから貼り付けてみてください。人事管理でよく使う社員名簿を想定したデータです。
| A列 | B列 | C列 | D列 | E列 | F列 |
| 社員番号 | 氏名 | 部署 | 役職 | 入社年月日 | 月給 |
| 1001 | 鈴木 一郎 | 営業部 | 部長 | 2022/04/01 | 500000 |
| 1002 | 佐藤 花子 | 開発部 | リーダー | 2023/10/01 | 380000 |
| 1003 | 高橋 健太 | 営業部 | 一般 | 2024/04/01 | 320000 |
【リスク】第3引数を「省略」した場合
QUERY関数は、第3引数を省略しても、このサンプルのようにデータ型が明確な場合は賢く自動で判断し、正しく動作することがあります。
しかし、それはあくまで「自動判断」であり、もし社員番号にテキスト(例: 'S-1001')が混じっていたり、データの形式が複雑だったりした場合には、見出しをデータの一部と誤認したり、予期せぬエラーが発生したりする「リスク」が常に伴います。
安定した動作のためには、第3引数を省略せず、明確に指示を与えることが非常に重要です。
【確実な成功例】第3引数に「1」を指定する
安定した結果を得るための最も確実な方法は、第3引数に「1」(1行目が見出し、という意味)を指定することです。
=QUERY(A:F, "SELECT A, B, F WHERE A IS NOT NULL", 1)
結果
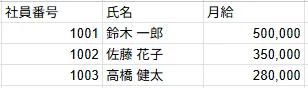
このように、第3引数に1を指定すれば、スプレッドシートは混乱することなく、1行目を見出しとして正しく認識し、結果の先頭に表示してくれます。
これが、QUERY関数が100%正しく動作している「成功」の状態です。
【実用・応用編】見出しなしで「データ本体」だけ欲しい場合
では、この「見出しなし」の抽出は、一体どのような場面で役立つのでしょうか。
その代表的な例が、給与計算ソフトなど、外部システムへ取り込むためのインポートデータを作成する場合です。
多くの給与ソフトでは、インポートするCSVファイルの1行目の項目名(ヘッダー)が「社員コード」「氏名」「基本給」のように厳密に定められています。
このような場合、まず1行目には、ソフトの仕様書通りに手で項目名を入力しておきます。
そして、2行目のセルにQUERY関数を記述し、別の場所にある「社員名簿マスター」シートから、必要なデータだけを抽出・整形して流し込むのです。
=QUERY('社員名簿マスター'!A2:F, "SELECT A, B, F WHERE A IS NOT NULL", 0)
ポイント
- データ範囲を、見出しを含まない
'社員名簿マスター'!A2:Fから始める。 - その上で、この範囲には見出しが無いので、第3引数を
0に設定する。
結果

この方法を使えば、マスターデータは自由に管理しつつ、インポート用のデータはいつでも正確かつ最新の状態で出力できます。
手作業でのコピー&ペーストによるミスを防ぎ、給与計算業務を大幅に効率化できる、非常に実用的なテクニックです。
QUERY関数の主なコマンド【機能別リファレンス】
第3引数の重要性を理解できたら、次はクエリで使う主な命令句を簡潔に見ていきましょう。
これらを組み合わせることで、自在にデータを抽出できます。
- SELECT
- 機能: 必要な「列」だけを取り出す命令。
- 構文例:
=QUERY(A1:F4, "SELECT A, B, F", 1)- → A列(社員番号)、B列(氏名)、F列(月給)だけを抽出します。
- WHERE
- 機能: 条件に合う「行」だけを絞り込む命令。
- 構文例:
=QUERY(A1:F4, "SELECT * WHERE C = '営業部'", 1)- → C列(部署)が「営業部」の行だけを抽出します。
- ORDER BY
- 機能: 指定した列を基準にデータを並べ替える命令。
- 構文例:
=QUERY(A1:F4, "SELECT * ORDER BY E DESC", 1)- → E列(入社年月日)を基準に降順(新しい順)で並べ替えます。
- GROUP BY
- 機能: 指定した列の項目でデータをグループ化し、集計する命令。
- 構文例:
=QUERY(A1:F4, "SELECT C, AVG(F) GROUP BY C", 1)- → C列(部署)でグループ化し、それぞれの平均月給(AVG)を計算します。
- LABEL
- 機能: 抽出後のデータの「見出し」を分かりやすい名前に変更する命令。
- 構文例:
=QUERY(A1:F4, "SELECT C, AVG(F) GROUP BY C LABEL AVG(F) '平均月給'", 1)- →
AVG(F)の計算結果の見出しを「平均月給」に変更します。
- →
【まとめ】QUERY関数を制する者は、第3引数を制する
もし、あなたがQUERY関数のエラーで悩んだら、まずはクエリの中身を疑う前に、第3引数に「1」が正しく設定されているかを確認してみてください。
- 見出し付きで安全に抽出したい → 第3引数は
1 - 見出しなしでデータだけ欲しい → 範囲を
A2から始め、第3引数は0
この基本を押さえるだけで、あなたのデータ集計・分析業務は、見違えるほどスムーズになるはずです。
こうしたITツールを活用したバックオフィス業務の効率化について、さらに詳しく知りたい、自社に合った方法を相談したいという場合は、ぜひ社労士事務所ぽけっとへお気軽にお問い合わせください。
【免責事項】
本記事は、執筆時点の情報を基に作成しております。記事内で紹介しているGoogleスプレッドシートなどのツールは、アップデートによって機能や仕様が変更される可能性があり、本記事の内容が最新の挙動と異なる場合がございます。
情報の正確性には万全を期しておりますが、本記事の情報を利用して生じたいかなる損害(データの損失等を含む)についても、当事務所は一切の責任を負いかねます。操作を行う際は、ご自身の責任において、必要に応じてデータのバックアップを取るなどのご対応をお願いいたします。
労務管理に関する具体的なご相談は、当事務所までお問い合わせください。

